This is the first post in a series about running LLMs locally. The second part is about Connecting Stable Diffusion WebUI to your locally running Open WebUI .
We’ll accomplish this using
- A nix enabled machine
- An AMD GPU - a decent CPU will probably work as well
- Rootless docker
- Ollama/ollama
- Open-webui/open-webui
Rootless docker
You can enable rootless docker with the following nix configuration. Its a nice way of running docker without it needing root access. This reduces the blast radius if code should be able to break out of your containers in case of exploitable vulnerabilities.
This also means your user don’t need to be in the docker group, and you don’t need sudo to launch docker images.
virtualisation.docker = {
# must align with your filesystem
storageDriver = "btrfs";
rootless = {
enable = true;
# by default point DOCKER_HOST to the rootless Docker instance for users
setSocketVariable = true;
# where the data goes
daemon.settings = { data-root = "/data"; };
};
};
Start the docker daemon from your user account
systemctl --user start docker
Ollama
Ollama is one of many ways to get up and running with large language models locally. It works on both Windows, Mac and Linux, and can also run in docker. It also works alright with a decent CPU, if you don’t have a GPU at hand. (Of course, a GPU will make it much, much faster).
docker run -d -v ollama:/root/.ollama -p 11434:11434 --name ollama ollama/ollama
After this, you can install ollama from your favorite package manager, and you have an LLM directly available in your terminal by running ollama pull <model> and ollama run <model>. Try it with nix-shell -p ollama, followed by ollama run llama2.
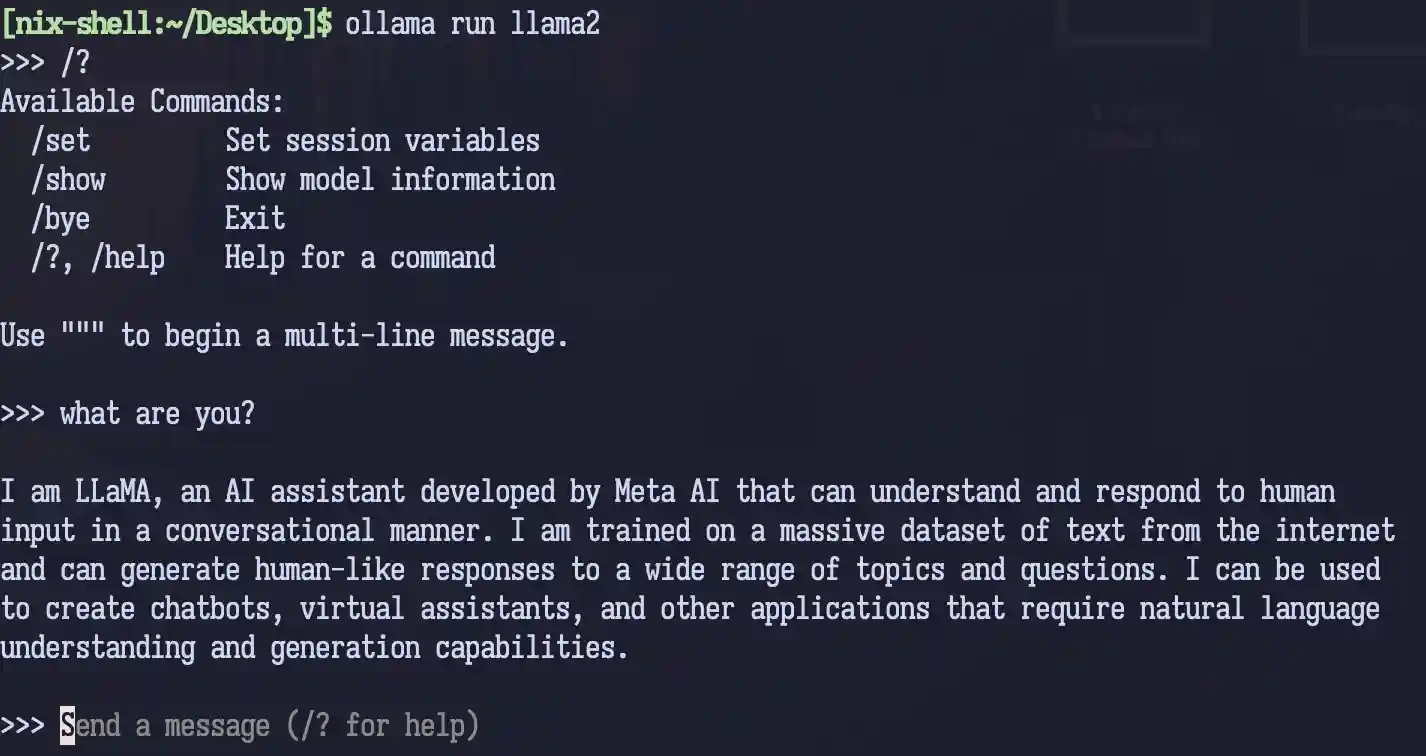
You can also script against it, e.g. by running this curl command - that makes sure to prevent buffering for both curl and jq, for that incredibly annoying OG chatbot feel.
curl http://localhost:11434/api/generate \
--no-buffer \
--silent \
-d '{ "model": "llama2", "prompt":"Why is the sky blue? Keep it brief." }' \
| jq --unbuffered -jrc .response
Already this is useful in and of itself, but adding open-webui to the mix you can take it even further, to create your own little chatgpt-like playground.
But I have a GPU
Check the docker hub image descriptions for the image variation you will need to detect and support your GPU automatically
For my AMD RX6800XT GPU, it was simply a matter of switching to the image ollama/ollama:rocm and forwarding the devices /dev/kfd and /dev/dri to make Ollama detect it.
This will speed your queries up by orders of magnitude.
Open-webui
Open-webui describes itself as
(…) an extensible, feature-rich, and user-friendly self-hosted WebUI designed to operate entirely offline. It supports various LLM runners, including Ollama and OpenAI-compatible APIs.
It also runs with docker
, and connects to your running ollama server. It provides a web based chat like experience, much like chatgpt - in fact, pretty much exactly like chatgpt.
I’m not conviced chats like this is the way to interact with AI. Nonetheless, this is where its at, and I have to say that the open source variant of the “chatgpt UI” does work pretty darn well.
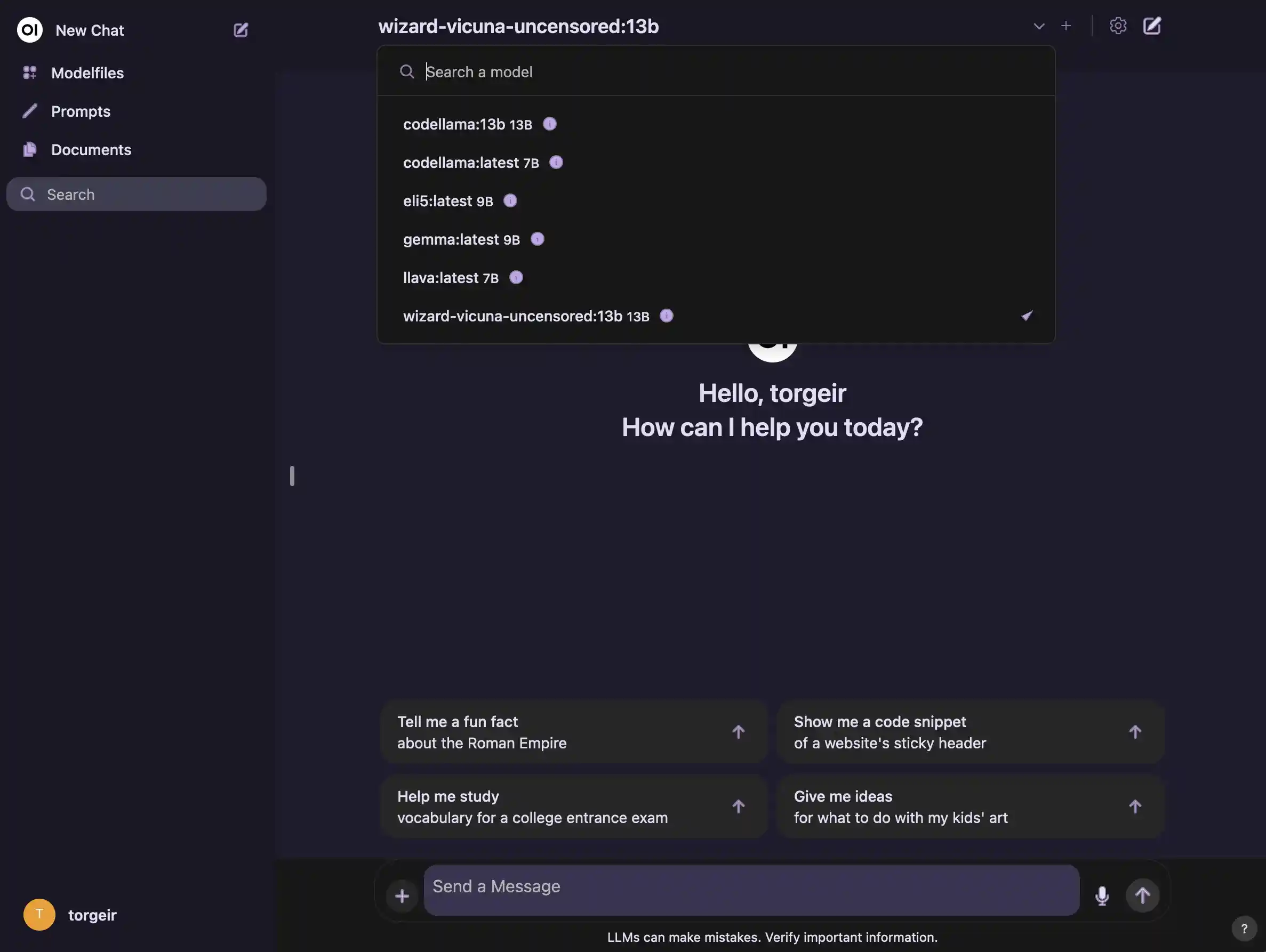
The webui brings life to a lot of the features of ollama. Among other things I like, it enables
- user registration with an admin interface, so you could share the instance with your friends and family at home
- pulling models automatically from the Ollama library
- uploading files for context, that the models can query
- chat configurations, supporting predefined models and prompts to customize your assistants
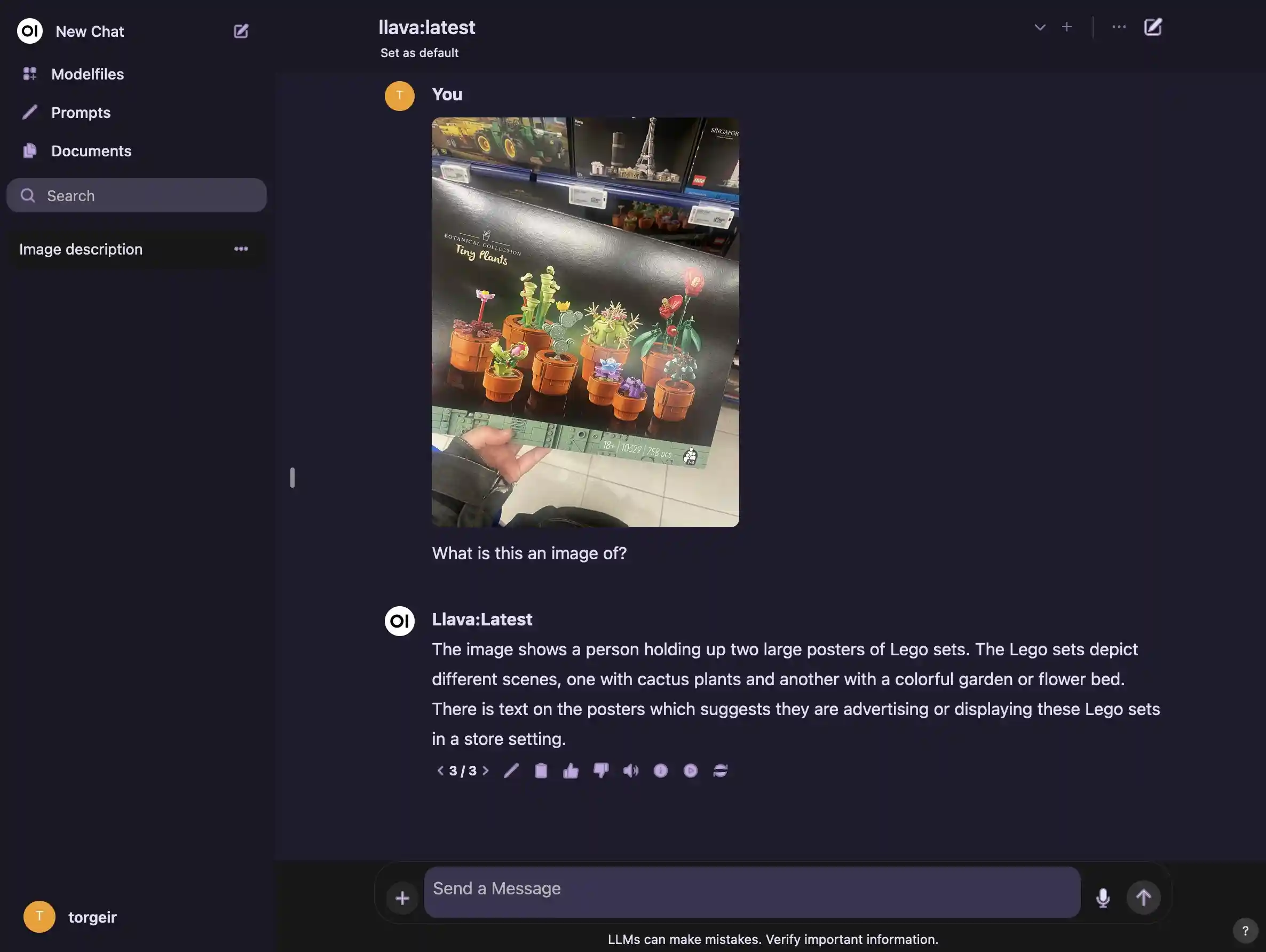
- with a model like
llava, it can look at and understand images
Well, almost.
It can even connect to the AUTOMATIC1111/stable-diffusion-webui
to enable image generation, but sadly support for rocm and AMD GPUs are still lacking in the docker variant of stable-diffusion-webui, so that’s for another post.
docker-compose.yml
If all this sounds interesting, here is the docker compose configuration needed to run ollama and open-webui on NixOs with rootless docker and an AMD graphics card.
# docker-compose.yml
services:
ollama:
container_name: ollama
image: ollama/ollama:rocm
restart: unless-stopped
expose:
- 11434:11434
devices:
- /dev/kfd
- /dev/dri
volumes:
- ollama:/root/.ollama
networks:
- internal
open-webui:
container_name: open-webui
image: ghcr.io/open-webui/open-webui:main
restart: unless-stopped
volumes:
- open-webui:/app/backend/data
depends_on:
- ollama
environment:
- "OLLAMA_BASE_URL=http://ollama:11434"
ports:
- 8080:8080
networks:
- internal
volumes:
ollama: {}
open-webui: {}
networks:
internal:
driver: bridge
Put it in a folder and run docker compose up inside it.
But I am using Emacs
Check out ellama on MELPA, or s-kostyaev/ellama
, for instructions on how to integrate this into your workflow.
Have fun! 🤖