This is the second post in a series about running LLMs locally. Part one was about Running LLMs locally with Ollama and open-webui .
After digging through a bunch of dependency mismatch errors with the pip packages needed for AUTOMATIC1111/stable-diffusion-webui to run inside a docker container, I finally got it working. Still inside rootless docker, following up what we did in part one.
Stable Diffusion WebUI in docker
I’ll spare you the details, mainly because I don’t remember them tbh, and I didn’t keep note of the links. It was a mix of reading through stable-diffusion-webui GitHub issues, python stack traces, and me semi-blindly trying different modifications and versions of the packages that were complaining, based on suggestions across different GitHub issues.
Here’s a Dockerfile with the nescessary changes to get Stable Diffusion WebUI running inside Docker (rootless). It clones the project and fixes some of the problematic dependencies. What does it do?
- it locks fastapi to version 0.90.1
- it locks pytorch_lightning to version 1.6.5
- it adds a missing dependency for timm
The Stable Diffusion WebUI wiki running in Docker-guide also mention a few other parameters that I did not find nescessary, like relaxing the default seccomp profile , that seems to stem from the rocm/pytorch dockerhub readme .
The launch CMD also need a few command line parameters to be useful
--listen, so it binds to0.0.0.0and can be used from outside the docker container--api, so it starts the api, that Open WebUI will use to generate images with it--data, to tell Stable Diffusion WebUI where to keep its data
FROM rocm/pytorch
RUN cd / \
&& git clone https://github.com/AUTOMATIC1111/stable-diffusion-webui \
&& cd stable-diffusion-webui \
&& python -m pip install --upgrade pip wheel \
&& sed -i '/fastapi/c\fastapi==0.90.1' requirements.txt \
&& sed -i '/pytorch_lightning/c\pytorch_lightning==1.6.5' requirements.txt \
&& echo >> requirements.txt \
&& echo timm >> requirements.txt
WORKDIR /stable-diffusion-webui
ENV REQS_FILE='requirements.txt'
CMD ["python", "launch.py", "--listen", "--api", "--data", "/data/stable-diffusion-webui/models"]
Testing it
Put the Dockerfile in a folder, build the image, start the container and visit https://localhost:7860.
docker build . -t sd-webui
docker run -d sd-webui
It should show Stable Diffusion WebUI.
Test it with something like this - the things you have to prompt to get good images from stable diffusion is hilarious.
((masterpiece)), surrealist treetop village, amazing detail, artstation, (punkwave:1.3), 70mm canon, warm lighting, sunset, woodland, bokeh effect
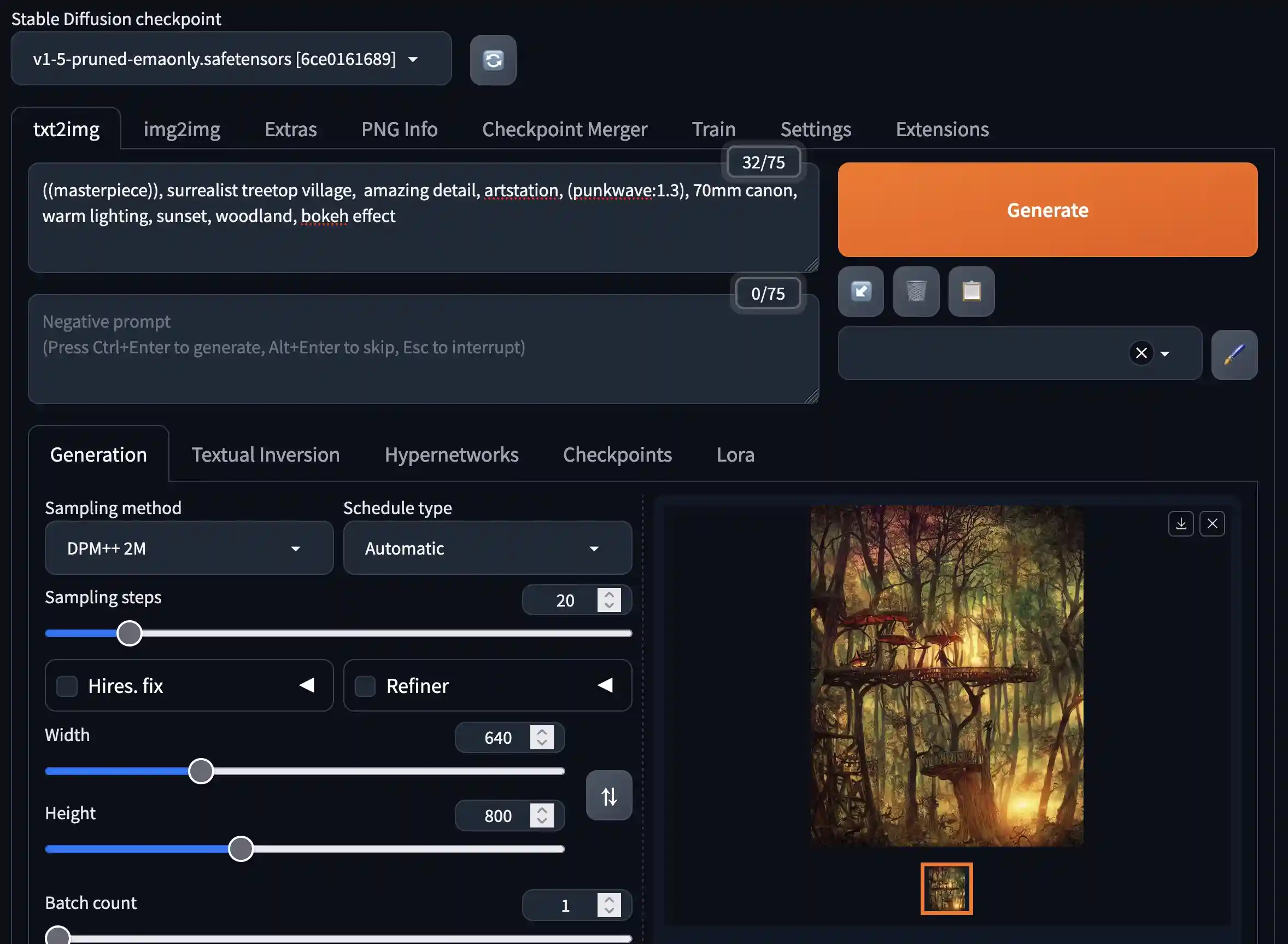
The results are pretty good, though!

Making Open WebUI talk to the Stable Diffusion API
Making Open WebIU aware of the Stable Diffusion API is really just about making the services discoverable by one another, and pointing them in the correct direction, as suggested in the docs on image generation .
I combined the above configuration with the last setup for ollama and open-webui
, using docker compose, to make all these services talk to one another inside a private network. The most interesting parts of this configuration is the environment variables given to Open WebUI to discover the Stable Diffusion API, and turn on Image Generation.
- "AUTOMATIC1111_BASE_URL=http://sd-webui:7860/"
- "ENABLE_IMAGE_GENERATION=true"
- "IMAGE_GENERATION_MODEL=v1-5-pruned-emaonly"
- "IMAGE_SIZE=640x800"
The setup that follows is a mouthful, as I also started playing around with a Docker label-based setup of the reverse-proxy Traefik - sorry about that. In short it sets up each service, a volume for each of them to keep their data, and exposes their internal port mapping only to Traefik on an internal network. Traefik then serves each of them out of the container:
- stable-diffusion-webui: https://localhost:7860/
- open-webui: https://localhost/
- ollama: http://localhost:11434/ (on http to play nice with s-kostyaev/ellama )
# docker-compose.yml
services:
sd-webui:
build:
context: .
dockerfile: Dockerfile
expose:
- 7860:7860
devices:
- /dev/kfd
- /dev/dri
networks:
- internal
restart: unless-stopped
volumes:
- sd-webui:/data/stable-diffusion-webui/models
labels:
- traefik.enable=true
- traefik.http.routers.sd-webui.rule=Host(`localhost`)
- traefik.http.routers.sd-webui.entrypoints=sd-web
- traefik.http.routers.sd-webui.tls=true
- traefik.http.services.sd-webui.loadbalancer.server.port=7860
ollama:
container_name: ollama
image: ollama/ollama:rocm
expose:
- 11434:11434
devices:
- /dev/kfd
- /dev/dri
volumes:
- ollama:/root/.ollama
networks:
- internal
restart: unless-stopped
labels:
- traefik.enable=true
- traefik.http.routers.ollama.rule=Host(`localhost`)
- traefik.http.routers.ollama.entrypoints=web-insecure
- traefik.http.services.ollama.loadbalancer.server.port=11434
open-webui:
container_name: open-webui
image: ghcr.io/open-webui/open-webui:main
volumes:
- open-webui:/app/backend/data
depends_on:
- ollama
environment:
- "ENABLE_SIGNUP=true"
- "OLLAMA_BASE_URL=http://ollama:11434"
- "AUTOMATIC1111_BASE_URL=http://sd-webui:7860/"
- "ENABLE_IMAGE_GENERATION=true"
- "IMAGE_GENERATION_MODEL=v1-5-pruned-emaonly"
- "IMAGE_SIZE=640x800"
expose:
- 8080:8080
networks:
- internal
restart: unless-stopped
labels:
- traefik.enable=true
- traefik.http.routers.open-webui.rule=Host(`localhost`)
- traefik.http.routers.open-webui.entrypoints=web
- traefik.http.routers.open-webui.tls=true
- traefik.http.services.open-webui.loadbalancer.server.port=8080
traefik:
image: traefik:2.10.4
command:
- --log.level=DEBUG
- --accessLog=true
- --providers.docker=true
- --providers.docker.network=internal
- --providers.docker.exposedbydefault=false
- --entrypoints.web.address=:80
- --entrypoints.sd-web.address=:7860
- --entrypoints.web-insecure.address=:11434
# enables insecure mgmt api on 8080
- --api.insecure=true
ports:
- 8443:80
- 8444:8080
- 11434:11434
- 7860:7860
networks:
- internal
restart: unless-stopped
volumes:
- /run/user/1000/docker.sock:/var/run/docker.sock:ro
volumes:
ollama: {}
open-webui: {}
sd-webui: {}
networks:
internal:
driver: bridge
What’s with the Traefik setup?
I just wanted to test it, really. Configuring a reverse-proxy based on Docker labels alone seems like a nifty idea. I like it.
In short, each service configures a named router, a hostname, tls yes/no and an entrypoint, and the main Traefik service map these entrypoints to the ports external to the container. This way Traefik is the only service that forward its ports out of the internal network - note its use of the ports directive, while the other services use expose to keep them internal on the private docker network.
These services are served using the Traefik self-signed certificate at the moment. Fixing that to use something like Let’s Encrypt might be fun, but that’s for another post.
Open WebUI configuration
For some reason, Open WebUI seems to not automatically discover the Stable Diffusion API and the configured image generation settings. I have not yet figured out why, but suspect it has to do with the port being part of the url. We’ll help it discover the image generation model by turning the feature on again, like you really mean it, and reload the configuration. I clicked the ON button, followed by the reload button 🔁, and hit Save.
Now explain to Llama3 what you’d like to see.
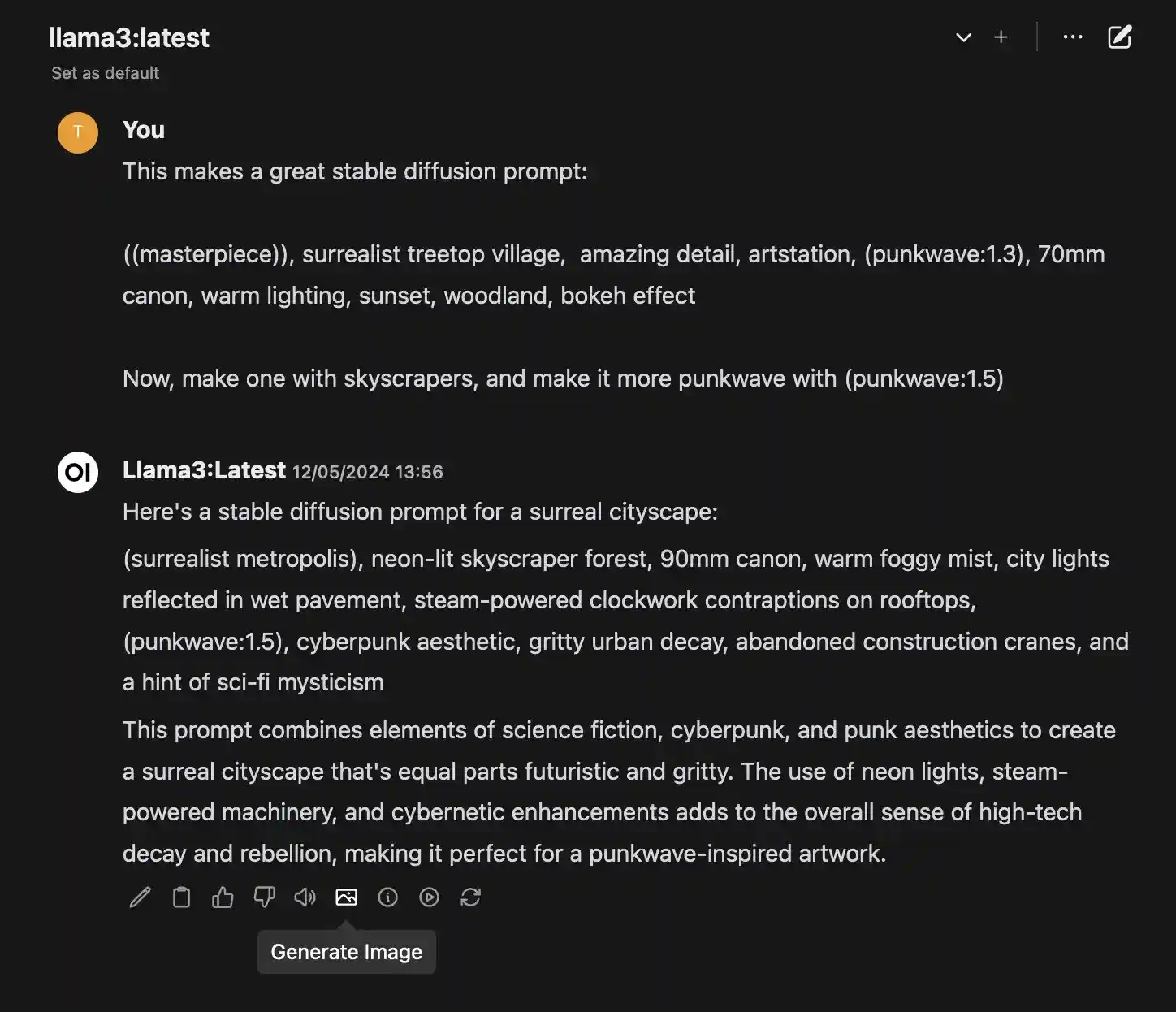
And click Generate Image to have your locally running assistant generate an image based on this for you. I believe the prompt in its entirety is sent to the Stable Diffusion API. If you really wanted to be specific, you could probably prompt it to output only the prompt part of its response. But this works fine, too
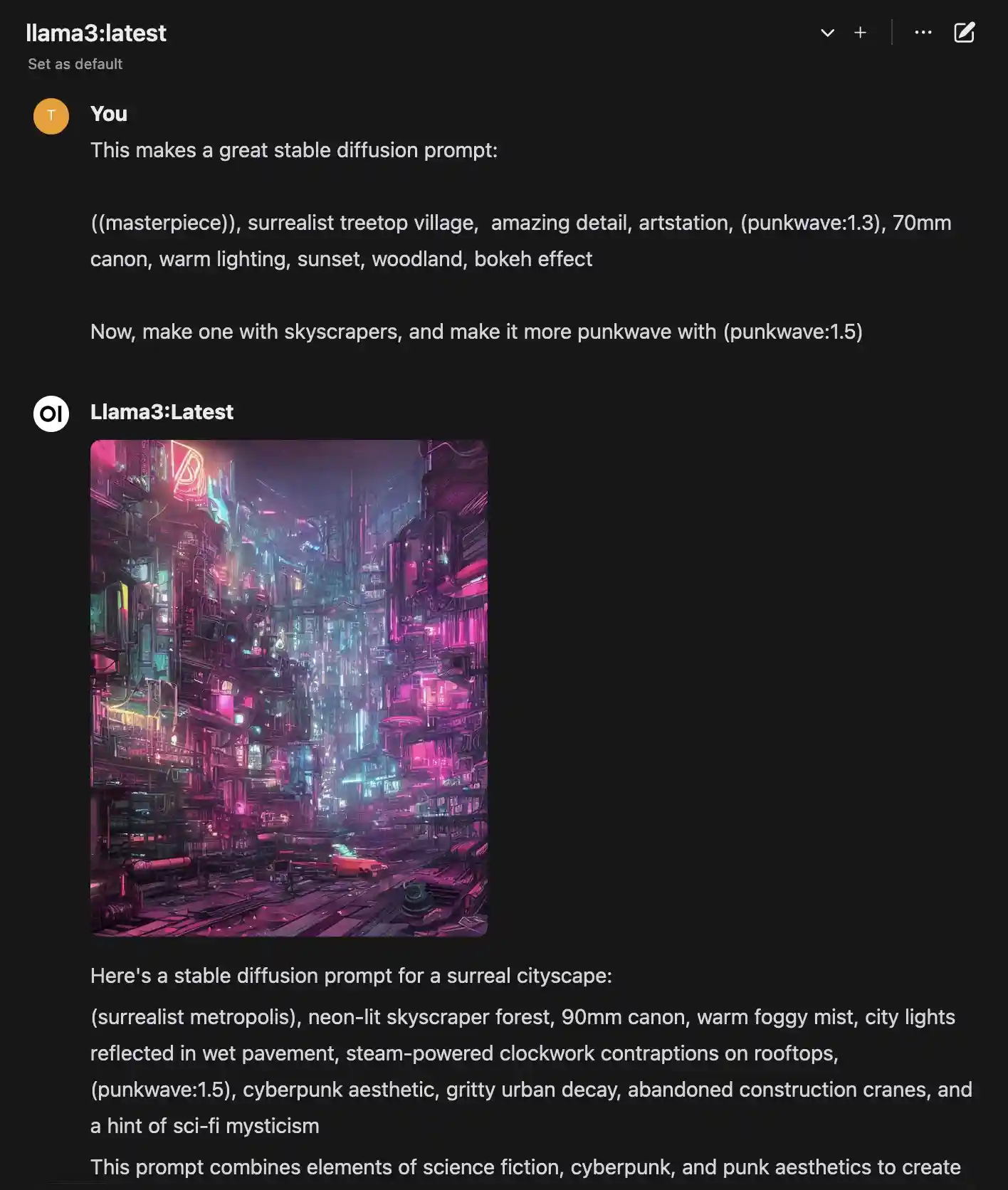
Looks pretty darn good if you ask me! If you’re unhappy with it, click it again to replace the previously generated image with a new one. This was a 640x800 render, just for the sake of the example. It took about 15 seconds using the RX6800XT GPU.

Next up!
While the Llama3 is not nearly as competent as ChatGPT 4 - I’ve seen people compare it to ChatGPT 3.5 - its still plenty good for my regular AI use as of today, like helping with code questions and summarizing news articles or those mile-long hackernews threads you just would like to skim. Now, with the added ability to play around with AI generated images locally, I’m seriosly considering terminating my ChatGPT subscription, at least until they release the next killer feature™.
I will definitely be setting up Tailscale to access this setup from remote. It should also work fine to connect ollama to Emacs via s-kostyaev/ellama from remote.
More on that later!
🌄🤖🌇